
天下一プログラミングコンテスト2013 予選A
D.天下一展開解説
[問題文]この問題は構文解析ならびにデータ構造についての実装を必要とする問題です。入力の文字列を解析する部分、解析結果からある一部を切り出す部分に分かれるかと思います。それぞれの効率によって部分点が分かれます。
部分点解法(50点)
文字列の長さは圧縮前、圧縮後ともに充分に小さいものとなっているので、圧縮前の文字列を復元すれば解くことができます。
部分点解法(50点+50点)
圧縮前の長さが充分に大きくなっています。これは50点の部分点と違い、圧縮前の文字列全体の復元はできないことを意味します。データ構造を用いて、圧縮前の文字列を復元せずにある位置の文字を求める必要があります。これには例えば、下図の様な木構造が有効です。
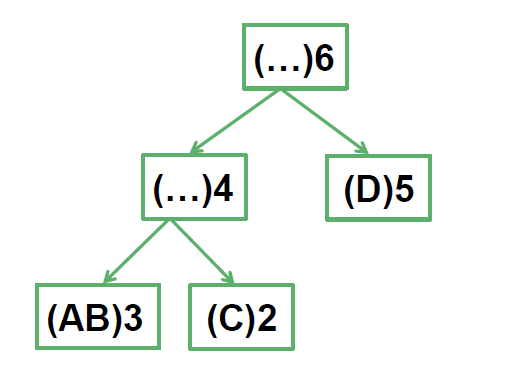
これは、"((AB)2)4(D)5)6"を表現したものです。ある頂点が表現する文字列の長さは、子の表現する文字列の長さと、その繰り返し回数から計算することができます。つまり、どの子がある位置の文字を含んでいるか計算することできるということになります。
満点解法
満点解法では、圧縮後の文字列の長さが大きくなっています。この場合、木構造の構築に一工夫を加える必要があります。下記の様な充分にネストがされている入力を考えてみます。
(((((((((((((((((((((((((((((((((A)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)1)10000000
この様な入力に対して単純に木構造を構築すると、木の高さがネストの分だけ高くなります。木の高さをHとした場合、解答の生成にはO(H*L)かかってしまいます。そこで、"圧縮前の文字列の長さは 1015 を超えない"ことに着目します。1015 < 250ということを考えると、入力が長くなる場合は必ず、(xxx)1といったような部分が大量に含まれていることになります。意味のある最小の繰り返し回数である2を使ったとしても、高さは50程度にしかならないからです。"((AA)1)1"と"(AA)1"は展開してしまえば等価です。1回の繰り返し部分を前もって展開すると、木の高さを抑えることにより高速化が可能になります。また、もう1つ注意すべきケースが存在します。"(A)1(B)1(C)1(D)1....(Z)1"といった様な、子を大量に持つ頂点の存在です。これも、実装によっては時間制限を超えてしてしまう可能性が考えられます。
予選A解説:[A] [B] [C] [D] [E(PDF)]
[トップページ]